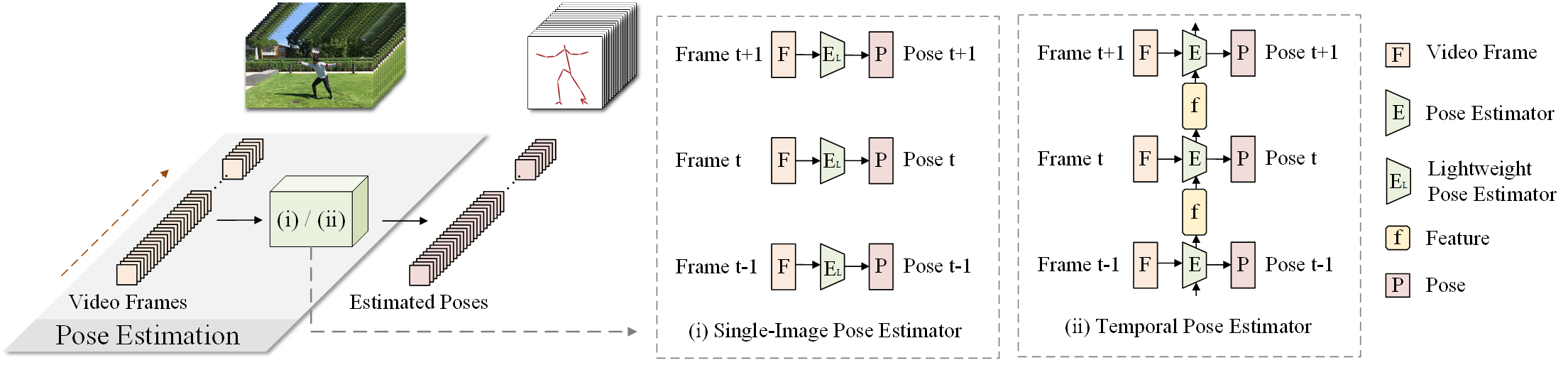
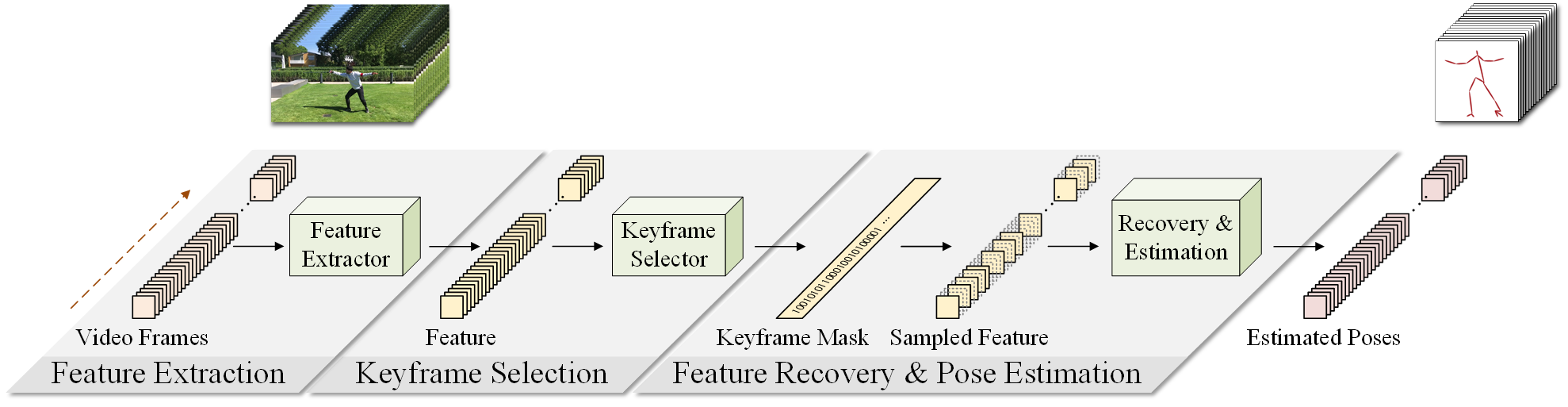
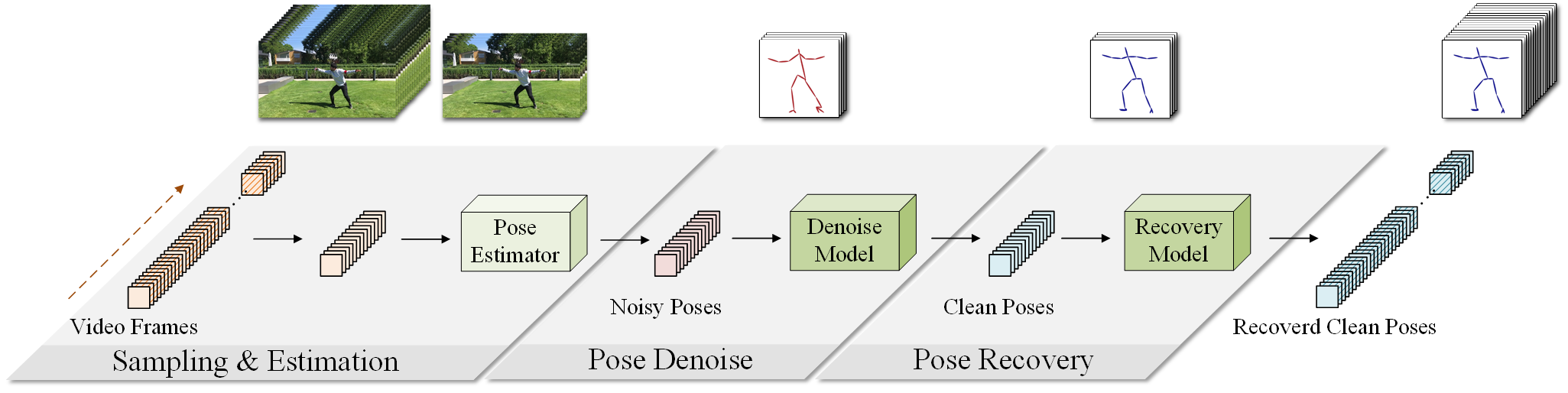
This paper proposes a simple baseline framework for video-based 2D/3D human pose estimation that can achieve 10 times efficiency
improvement over existing works without any performance degradation, named DeciWatch. Unlike current solutions that estimate each frame in a video,
DeciWatch introduces a simple yet effective sample-denoise-recover framework that only watches sparsely sampled frames, taking advantage of the
continuity of human motions and the lightweight pose representation. Specifically, DeciWatch uniformly samples less than 10% video frames
for detailed estimation, denoises the estimated 2D/3D poses with an efficient Transformer architecture,
and then accurately recovers the rest of the frames using another Transformer-based network. Comprehensive experimental results on three
video-based human pose estimation, body mesh recovery tasks and efficient labeling in videos with four datasets validate the efficiency
and effectiveness of DeciWatch.
Figure 1. Comparison of (a) SimplePose[1] to watch every frame [the red box indicates the frame to input poses for (b) DeciWatch]; (b) Our proposed DeciWatch to denoise and recover 2d poses; (c) ground truth.
Figure 2. Comparison of (a) SimplePose[1] to watch every frame [the red box indicates the frame to input poses for (b) DeciWatch]; (b) Our proposed DeciWatch to denoise and recover 2d poses; (c) ground truth.
Figure 3. Comparison of (a) SimplePose[1] to watch every frame [the red box indicates the frame to input poses for (b) DeciWatch]; (b) Our proposed DeciWatch to denoise and recover 2d poses; (c) ground truth.
Figure 4. Comparison of 3D Pose Estimation (3d positions from SPIN[2]) with (a) Watch-every-frame (100%) of SPIN,
(b) uniform sampling 10% of SPIN, (c) recovery by linear interpolation, (d) recovery by quadratic interpolation, (e) recovery by DeciWatch and (f) ground truth on the AIST++ dataset.
Figure 5. Comparison of 3D Pose Estimation (3d positions from SPIN[2]) with (a) Watch-every-frame (100%) of SPIN,
(b) uniform sampling 10% of SPIN, , (c) recovery by linear interpolation, (d) recovery by quadratic interpolation, (e) recovery by DeciWatch and (f) ground truth on the AIST++ dataset.
Figure 5. Comparison of 3D Pose Estimation (3d positions from FCN[3]) visualized from the camera view and bird view on the Human3.6M dataset.
Figure 6. Comparison of human body recovery method (PARE[4]) with DeciWatch (Recover from 10% frames of 6d rotation matrices) on the 3DPW dataset.
Figure 7. Comparison of human body recovery method (PARE[4]) with DeciWatch (Recover from 10% frames of 6d rotation matrices) on the 3DPW dataset.
Figure 8. Comparison of human body recovery method (PARE[4]) with DeciWatch (Recover from 10% frames of 6d rotation matrices) on the 3DPW dataset.
Why is DeciWatch not only efficient but also effective?
Two failure cases
When the sampling rate is much lower than the motion frequency of some body parts (e.g., hands), it will be difficult to supplement the actual motion.
If the estimated poses of most visible frames in the sliding window are in large errors, it is hard to recover the correct poses.
References
[1] Xiao, B., Wu, H., Wei, Y.: Simple baselines for human pose estimation and tracking.
In: Proceedings of the European conference on computer vision (ECCV). (2018)
[2] Kolotouros, N., Pavlakos, G., Black, M.J., Daniilidis, K.: Learning to reconstruct 3d human pose and shape via model-fitting in the loop.
In: Proceedings of the IEEE/CVF International Conference on Computer Vision. (2019)
[3] Martinez, J., Hossain, R., Romero, J., Little, J.J.: A simple yet effective baseline for 3d human pose estimation.
In: Proceedings of the IEEE International Conference on Computer Vision.(2017)
[4] Kocabas, M., Huang, C.H.P., Hilliges, O., Black, M.J.: Pare: Part attention regressor for 3d human body estimation.
In: Proceedings of the IEEE/CVF International Conference on Computer Vision. (2021)
BibTeX
@inproceedings{zeng2022deciwatch,
title={DeciWatch: A Simple Baseline for 10x Efficient 2D and 3D Pose Estimation},
author={Zeng, Ailing and Ju, Xuan and Yang, Lei and Gao, Ruiyuan and Zhu, Xizhou and Dai, Bo and Xu, Qiang},
booktitle={European Conference on Computer Vision},
year={2022},
organization={Springer}}