SmoothNet
A Plug-and-Play Network for Refining Human Poses in Videos
1 The Chinese University of Hong Kong
2 Sensetime Group Ltd.
3 Shanghai Jiao Tong University 4 Nanyang Technological University
3 Shanghai Jiao Tong University 4 Nanyang Technological University
Abstract
When analyzing human motion videos, the output jitters from existing pose estimators are highly-unbalanced with varied estimation errors across frames.
Most frames in a video are relatively easy to estimate and only suffer from slight jitters. In contrast, for rarely seen or occluded actions,
the estimated positions of multiple joints largely deviate from the ground truth values for a consecutive sequence of frames,
rendering significant jitters on them.
To tackle this problem, we propose to attach a dedicated temporal-only refinement network to existing pose estimators for jitter mitigation,
named SmoothNet. Unlike existing learning-based solutions that employ spatio-temporal models to co-optimize per-frame precision and temporal
smoothness at all the joints, SmoothNet models the natural smoothness characteristics in body movements by learning the long-range temporal
relations of every joint without considering the noisy correlations among joints. With a simple yet effective motion-aware fully-connected network,
SmoothNet improves the temporal smoothness of existing pose estimators significantly and enhances the estimation accuracy of those challenging
frames as a side-effect. Moreover, as a temporal-only model, a unique advantage of SmoothNet is its strong transferability across various types
of estimators and datasets. Comprehensive experiments on five datasets with eleven popular backbone networks across 2D and 3D pose estimation and
body recovery tasks demonstrate the efficacy of the proposed solution.
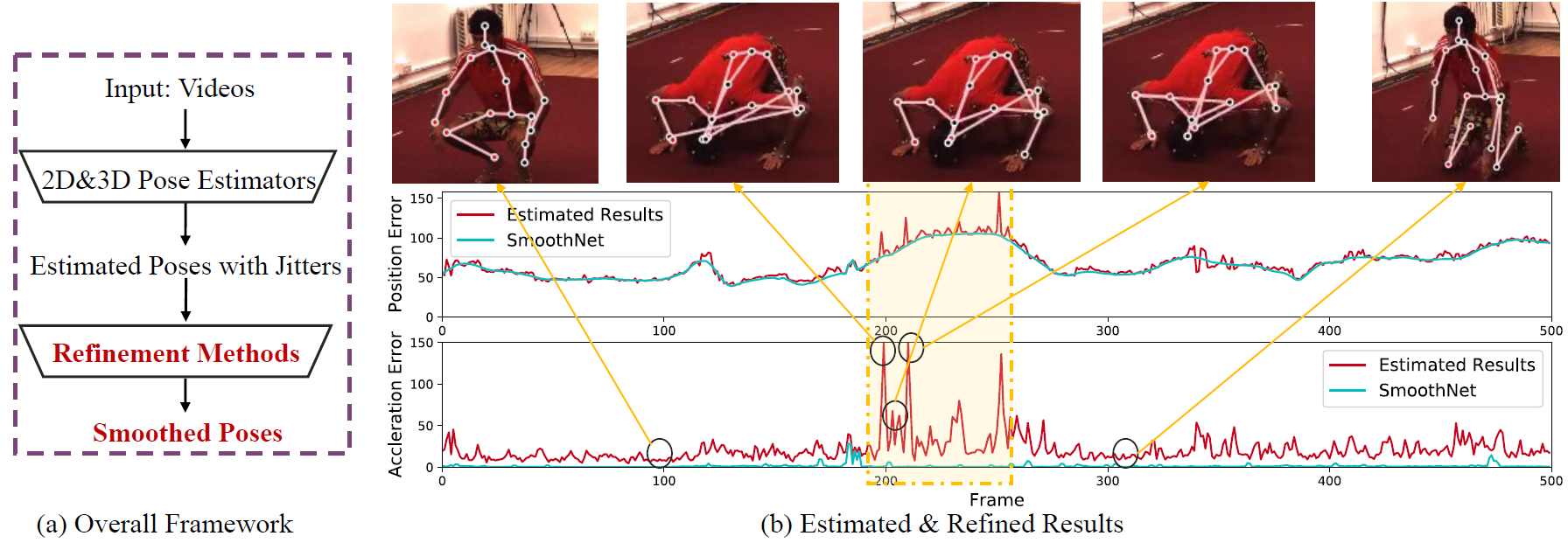
Demo of SmoothNet
Qualitative Results
Downstream task: Skeleton-based action recognition
BibTeX
@inproceedings{zeng2022smoothnet,
title={SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos},
author={Zeng, Ailing and Yang, Lei and Ju, Xuan and Li, Jiefeng and Wang, Jianyi and Xu, Qiang},
booktitle={European Conference on Computer Vision},
year={2022},
organization={Springer}}
Contact
For any questions, please contact Ailing Zeng (alzeng@cse.cuhk.edu.hk).